– Writted by Edward Currie –
Large-scale websites encounter distinct challenges in the realm of technical SEO. Whether you are overseeing a significant e-commerce platform or an international travel website, it is vital to manage the technical elements to maintain search visibility, ensure crawlability and enhance user experience. In this article, we will explore the fundamental technical SEO best practices specifically tailored for intricate, large-scale websites.
A well-structured site architecture forms the cornerstone of SEO success for extensive websites. With the possibility of having thousands of pages to oversee, it is crucial to ensure that search engines can readily crawl and comprehend your site.
Organising site structure
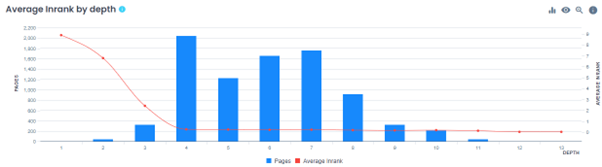
A clean and logical hierarchy that ensures crucial content is accessible within three clicks from the homepage can enhance both user experience and search engine crawling efficiency. Employ descriptive categories and subcategories to organise content effectively. If you manage large-scale websites, you might have encountered a graph similar to the one shown below.
A common challenge for expansive websites is the lack of adequate technology or site structure to support growth in an SEO-friendly manner. As websites expand, it is imperative that the site structure is set up to accommodate this growth, ensuring that important pages remain easily accessible to users and search engines alike.
The example below illustrates how the majority of pages are not within Google’s recommended three-click rule. Investing in the technological setup, navigation and search functionalities can assist growing websites in maintaining a robust SEO foundation, supporting the indexability of vital pages and offering a positive user experience.
 Breadcrumbs and internal linking
Breadcrumbs and internal linking
Implementing breadcrumbs and a strong internal linking strategy enhances the ability of both users and search engines to navigate your site more efficiently. This approach minimises the risk of orphaned pages – those without any inbound links – and ensures the even distribution of link equity across your site. Google relies on intenal links to crawl a website and identify pages for indexing, which means having a coherent internal linking structure also improves a site’s indexability and helps your content achieve higher rankings in Google searches.
Breadcrumbs significantly support your internal linking framework by providing users and search engines with a straightforward method to logically navigate the website and locate relevant pages on their journey.
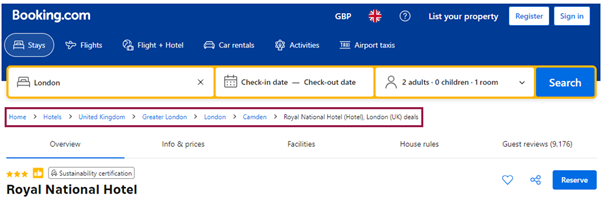 Example of breadcrumbs on the Booking.com website
Example of breadcrumbs on the Booking.com website
XML sitemaps
A frequently overlooked aspect of a website’s technical setup is the effective use of the XML sitemap. As previously mentioned, larger websites may face challenges with pages being buried deep within the site architecture, making them less accessible to users and indicating to Google that these pages might not be important. Therefore, XML sitemaps are vital for ensuring that large websites allow search engines to discover all their content. An XML sitemap is a file that lists all the important pages on a website. In addition to crawling a site through its internal linking structure, Google utilises the XML sitemap to locate and identify pages and based on the sitemap’s configuration, it can gain a clearer understanding of your website’s structure.
For larger websites, it is advisable to split your XML sitema into separate files for different categories of pages, such as products, categories and blog posts, ensuring each remains under 50,000 URLs to prevent crawling issurs. A Sitemap Index File can then be used to house links to all the individual sitemaps that have been created. Once your XML sitemap(s) are established and if necessary, organised within a sitemap index file, it is recommended to test them prior to submitting them to Google. This testing can be conducted via Google Search Console.
 Crawl budget optimisation
Crawl budget optimisation Search engines assign a crawl budget to each website, which determines the frequency and depth of their crawling activities. For extensive sites, managing the crawl budget is crucial to ensure that your most important pages are indexed. Below, we’ve outlined some tips on how you can optimise the crawl budget for larger websites:
Prioritising high-value pages
Make sure that important pages, such as key product or service pages, are readily discoverable by search engines. As previously discussed, one method to achieve this is by establishing a robust internal linking structure and ensuring these pages are included in your sitemap. If you employ a mega menu, it is essential to link your priority pages from there.
Blocking low-value pages
Smaller websites may not need to overly concerned about the crawl budget, but as they expand, an increasing number of low-value pages might use up valuable crawl resources, preventing Google from discovering pages of higher value. A critical aspect of optimising a site generally involves reviewing which pages attract relevant traffic and which do not. For pages that fail to drive relevant traffic or any traffic at all, your process should involve identifying any pages that could benefit from content revamping, consolidating and redirecting outdated pages to more current versions and determining any pages that may be useful to users but are not intended for attracting organic traffic. For this latter category, it is advisable to use the robots.txt file or noindex tags to prevent Google from indexing these low-value pages. Examples of such pages could include login screens, filtered URLs or duplicate content generated by URL parameters. This approach frees up your crawl budget for the most important areas of your site.
Server performance
Slow-loading pages can adversely affect your crawl budget. If search engine bots encounter sluggish server responses, they might decrease the frequency with which they crawl your site. It is essential to optimise your servers to efficiently handle the volume of traffic. Tools such as PageSpeed Insights and GTmetrix can identify if your website is facing server-related issues, as demonstrated in the image below.
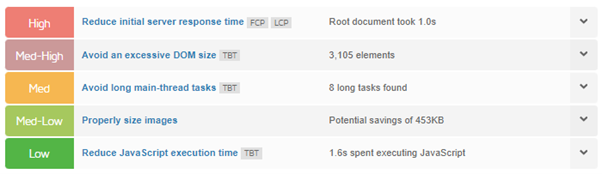 In this instance, you can implement server-side caching, which stores a pre-generated version of each page and presents it to users upon request. This approach relieves your server from having to load the page anew each time someone navigates to that page.
In this instance, you can implement server-side caching, which stores a pre-generated version of each page and presents it to users upon request. This approach relieves your server from having to load the page anew each time someone navigates to that page.
With the vast number of pages on a large website, indexing problems or duplicate content issues can easily arise. Proper canonicalisation ensures that the correct version of a page is indexed, thereby avoiding penalties associated with duplicate content.
Managing duplicate content
Duplicate content is one of the most prevalent issues on larger websites, primarily due to the sheer volume of pages requiring unique content.
Technical SEO tools often flag pages for duplicate content because they contain thin or insubstantial copy. If a page lacks sufficient content or the site uses repeated content sections across similar pages, it can confuse Google. This is because Google may struggle to determine the focus of the page and decide which pages to display in the Search Engine Results Pages (SERPs) for specific queries.
The straightforward solution is to create unique content for every page on a website, clearly indicating to both Google and users what the page is about. However, for larger websites that could potentially have millions of pages, this isn’t a simple task. The technical setup of some large websites might automatically generate new pages when specific criteria are met, resulting in a large number of pages with little to no content or even duplicated content.
One way to manage duplicate content is to use canonical tags on pages that are similar or have duplicated content, such as different product variations. This informs search engines about which version of the page should be indexed. Tools like Oncrawl and SEMrush can identify any duplicate content issues you may be experiencing on a website, as shown in the example below.
 Let’s consider a travel website as an example where canonical tags could effectively manage duplicate content. Suppose the site has pages for each room type within the same hotel, such as one-bed, two-bed and three-bed rooms, in addition to a page for the hotel itself. In this scenario, you could apply canonical tags to this set of pages to indicate to Google that the main hotel landing page should be the one to rank in the SERPs. While the other pages provide value to users, they are not intended to be ranked in the search results.
Let’s consider a travel website as an example where canonical tags could effectively manage duplicate content. Suppose the site has pages for each room type within the same hotel, such as one-bed, two-bed and three-bed rooms, in addition to a page for the hotel itself. In this scenario, you could apply canonical tags to this set of pages to indicate to Google that the main hotel landing page should be the one to rank in the SERPs. While the other pages provide value to users, they are not intended to be ranked in the search results.
URLs ought to be clean, descriptive and straightforward for both users and search engines to comprehend. For large websites, improper management of URL parameters can result in a range of SEO complications.
Creating SEO-friendly URLs
When crafting a new URL or a series of URLs, it is best practice to keep them concise and descriptive. Avoid including unnecessary parameters and ensure that URLs are consistently structured throuhgout your site. If you have a collection of pages related to a specific topic hub, make sure they are housed within the same subfolder. Referring back to our travel website example, you might find a /spain/ subfolder where the pages for Spanish cities are located, such as /spain/madrid or /spain/barcelona/.
Managing URL parameters
For e-commerce or other extensive sites with filtering options, mismanagement of URL parameters can result in the creation of multiple versions of the same page, leading to duplicate content issues. As mentioned earlier, these can be addressed by employing canonical tags or by configuring the parameters to be disregarded by search engines through the use of robots.txt file.
Large websites frequently encounter the challenge of managing 404 errors, which can occur due to outdated links, deleted content or incorrect URLs. The indexing report in Google Search Console (GSC) will be both your greatest ally and your greatest adversary when it comes to managing 404s, redirects and other indexing issues on your site. While it’s an excellent resource for identifying problems that need fixing, it can be quite overwhelming when dealing with large websites, which often have an array of indexing issues if not properly managed from an SEO perspective. Here are a few steps to help simplify and manage the process of clearing up your indexing report in GSC:
Monitoring and fixing 404s
Regularly monitor for 404 errors using tools such as GSC, Screaming Frog or Oncrawl. Address these issues by updating internal links that lead to 404 pages, implementing appropriate redirects for obsolete pages and removing URLs that return 404 status codes from your sitemaps.
301 vs 302 redirects
When redirecting pages, always use 301 redirects for permanent changes. Reserve 302 redirects for temporary changes only. When implementing a 301 redirect, utilise your technical SEO tools to identify any internal links pointing to the old URL and update them to link directly to the new URL. This practice helps to preserve link equity and prevent unnecessary redirect chains.
Although not exclusive to large websites, it is important to highlight the significance of structured data for SERP visibility. Structured data can aid search engines in better understanding your site’s content, enhancing visibility through rich snippets. In an era where zero-click searches are increasingly common, along with the rise of AI Overviews and Answer Snippets, every opportunity to provide Google with more information about your site, pages or products is valuable. Implementing schema markup can help your content stand out in search results and boost click-through rates to key pages.
Implementing structured data at scale
Implementing structured data across a large website can be daunting due to the sheer number of pages. To simplify this process, you can utilise tools like Google’s Structured Data Markup Helper or plugins designed for popular CMS platforms such as Schema Pro. At Passion Digital, we also offer a convenient Schema Builder that employs AI technology to assist you in creating the schema markup you require.
Common schema types include product, article, review and FAQ markup, all of which can enhance search results listings. For more information about various types of schema markup for B2B businesses, refer to our detailed guide.
Managing the technical SEO of a large and complex website demands meticulous attention to detail, proactive monitoring and the application of appropriate tools and expertise. While this guide outlines some key best practices to follow, there are additional factors to consider, such as log file analysis and specific international SEO strategies for large-scale websites.
By adhering to the aforementioned best practices, you will be better prepared to maintain your website’s efficiency, ensure that search engines can effectively crawl and index your content and ultimately improve your search visibility.
If you seek assistance with the SEO of your large-scale website, please contact our SEO team at Passion and we’ll be delighted to help!